
If you didn’t read the article about the HACL* approach, go there first and read it. tl;dr
HACL* is a cryptographic library written in F* that allows translation to C using kremlin. It guarantees memory safety, secret independent computation, and functional correctness with respect to a mathematical specification.
In this second blog post I describe the process of integrating code from HACL*, a researchy crypto library, into NSS, a production library shipping to millions of people, running on a plethora of platforms. In short, how to ship (some parts of) HACL*.
Shipping formally verified code
Before integrating any code from HACL* into NSS there had to be some criteria the code had to fulfil in order to get considered and a process of integrating, maintaining, and updating the code. The criteria roughly looked like this:
- The code has to be correct.
- Performance must not be degraded by any new code.
- The code has to be human readable and modifiable, i.e. it must pass a code review process.
- The code must run on all platforms supported by NSS or must have fallback code for platforms that are not supported.
- Upstream changes can to be integrated easily into NSS and fixes can be integrated upstream.
- The verification and generation toolchain has to run in the NSS world.
We started integrating HACL* crypto primitives into NSS with Curve25519. At the time of writing NSS contains code from HACL* for Curve25519 64-bit, Poly1305 32-bit and 64-bit, ChaCha20, and ChaCha20 with SSSE3 hardware acceleration. More primitives are in the pipeline and will be integrated in the near future.
Correctness
Any code that lands in NSS has to be correct, obviously. This might be evident but when talking about HACL* generated C code, correctness is not so simple. Correctness can be checked relatively easily by looking at the HACL* specification of a given primitive. This code is relatively easy to review (when familiar with F*) as it closely resembles the mathematical specification of the primitive. The correctness of the C code is guaranteed by the formal proofs from HACL*. In addition we run all the usual test vectors on it of course. To catch any errors in the extraction chain from F* to C the extracted C code is reviewed for correctness as well.
Performance
Performance was not a big concern. As shown in the HACL* paper from CCS 2017, performance of most primitives is on par with or better than the fastest C implementations out there. Nonetheless, performance of each primitive is compared between HACL* and the NSS to make sure not to degrade performance. For every primitive I looked at so far the performance of HACL* was at least as good as the performance of the NSS code.
Code quality
Code quality was, as with any generated code, a big concern. How readable is the generated code? Can it easily be changed if the need arises? The first versions we looked at weren’t that great …
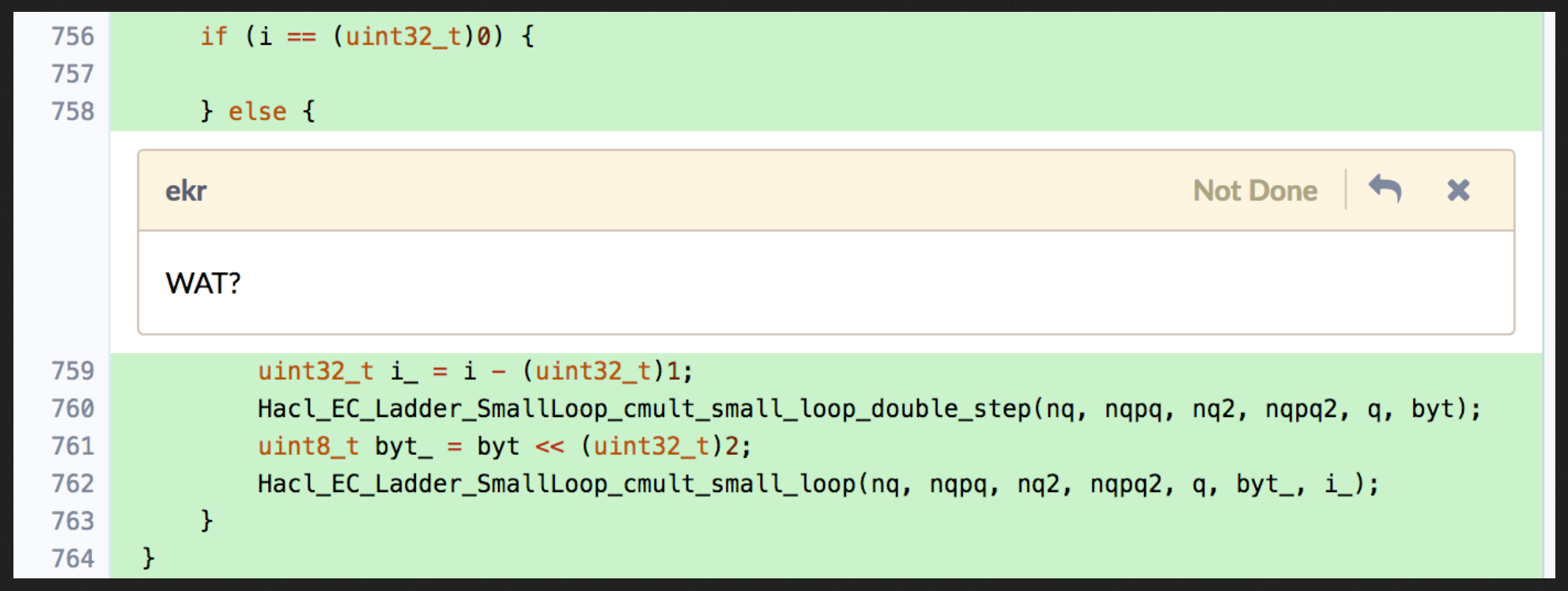

But after a couple improvements to kremlin the code was good to go. While every new piece of code that’s being integrated has to pass code review the C code produced by kremlin is good enough now to land new primitives without having to improve upstream code first. Note however that code passes review here that wouldn’t pass if it were hand-written. The code generator is not perfect. We have to live with some rough edges. The most important point is that the code is understandable.
NSS if formatted with clang-format, which is checked on CI.
So the only change to the verified C code imported from HACL* is formatting.
Some pain points remain
There are some outstanding issues that I hope get fixed in kremlin and would improve code quality significantly.
Kremlin doesn’t know const, which is one of the few nice helpers one can use in C to control what’s happening to your pointer.
While const is not necessary because of the HACL* proofs, it would be nice to have.
Kremlin further generates unnecessary casts such as (uint32_t)4U.
This is not a big deal but makes code harder to read.
There’s also a big number of temporary variables that aren’t necessary and make the code harder to read.
Platform support
Being a researchy library HACL* is not tested on a big variety of platforms. NSS on the other hand has to run on most available platforms as well as a number of legacy platforms. While the NSS CI covers Windows, Linux, and Mac in different configurations such as Intel 32-bit, 64-bit, and aarch64, there are other platforms such as BSD using NSS that are not covered. As expected we ran into a couple issues on some platforms such as BSD and Solaris but they were quickly resolved.


Especially code that is hardware dependent such as Intel intrinsics needs extra attention.
The vec128.h header used by HACL* to abstract hardware instructions needed a couple iterations before it worked on all supported platforms.
Handling change
The code imported from HACL* into NSS is not expected to change a lot. But there are always reasons why the code has to get updated and a process is required to do so. To fix issues like broken platforms, changes to the upstream projects have to be landed and the snapshot in NSS has to get updated to the new upstream version. For this process to run smoothly it’s necessary for both teams to work together.
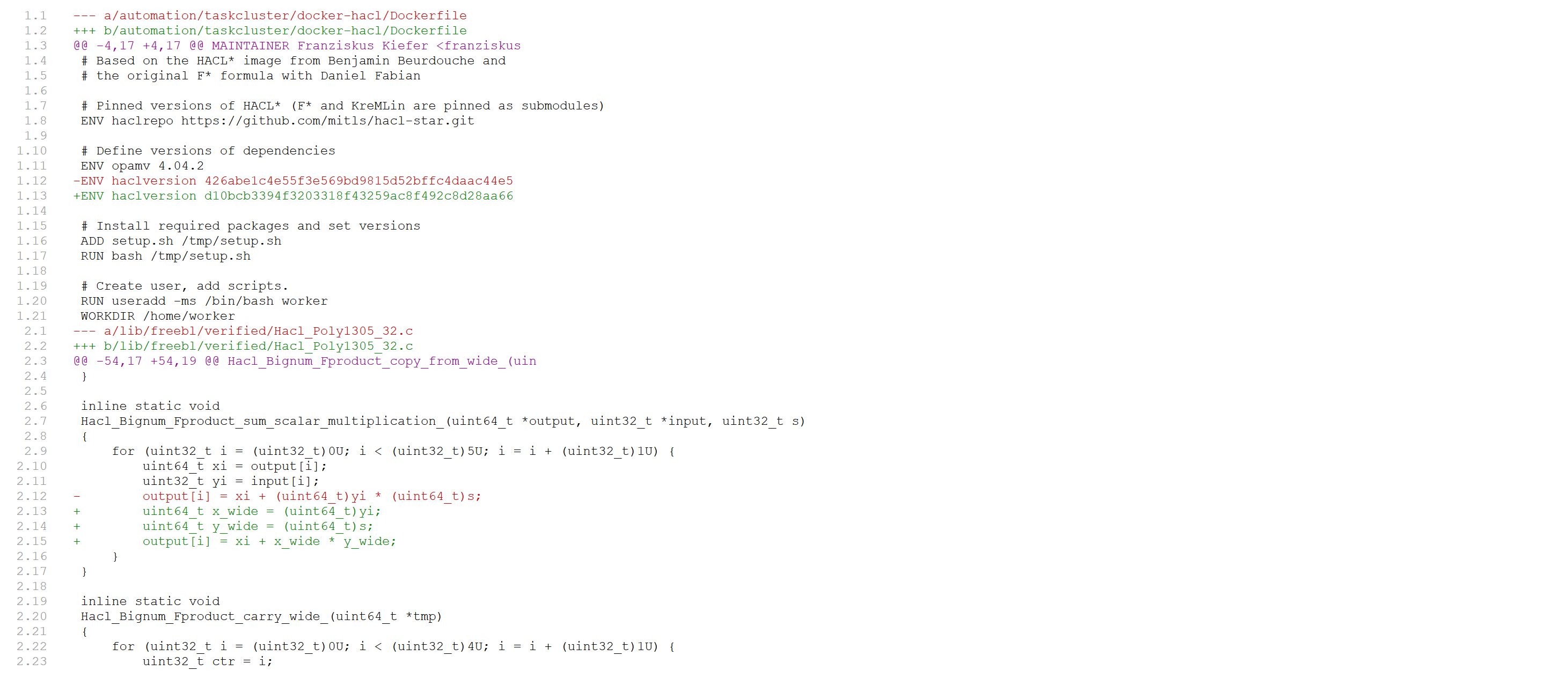
Updating the HACL* code in NSS is pretty easy. First the new code is generated with a new version of HACL*, formatted, and copied to NSS. Then the docker image running the CI gets updated. Here’s a diff for a recent update.
Running the verification in NSS
To make sure that whatever we use in NSS actually verifies and the generated code isn’t changed manually, the NSS CI has to verify the HACL* snapshot it uses on every run. NSS uses taskcluster as CI, which allows us to use a docker image that re-verifies the used HACL* revision on every push. Checking the code in NSS is then a simple diff.
Lessons learned
The first lesson is that it’s possible to ship formally verified software. The code is relatively simple and self-contained, which makes this easier. But it shows that formal verification tools are good enough to be used in production.
The second lesson we learned is probably the more valuable one.
Talk to each other and work together.
From an engineering standpoint it might be frightening to start looking at formal verification tools and corresponding languages. But people working with these tools are happy to help out if that means more people are using their tools. It will need some effort getting used to the tools and languages but it’s well worth it.
For people working on formal methods; You might have to learn a little more than you wanted to know about differences between different platforms and compilers and how to ship software. But that might be worth the effort if it means your proofs are used in production software that’s used by millions of people.
Looking for more material on this? There’s a high-level blog post that talks about the formal verification work in NSS happening at Mozilla. There has also been a talk at RWC 2018 earlier this year on this work (slides, video).